FinLMM-R1: Enhancing Financial Reasoning in LMM through Scalable Data and Reward Design
Jun 16, 2025·,,,,,·
0 min read
Kai Lan
Jiayong Zhu
Jiangtong Li
Dawei Cheng
Guang Chen
Changjun Jiang
Abstract
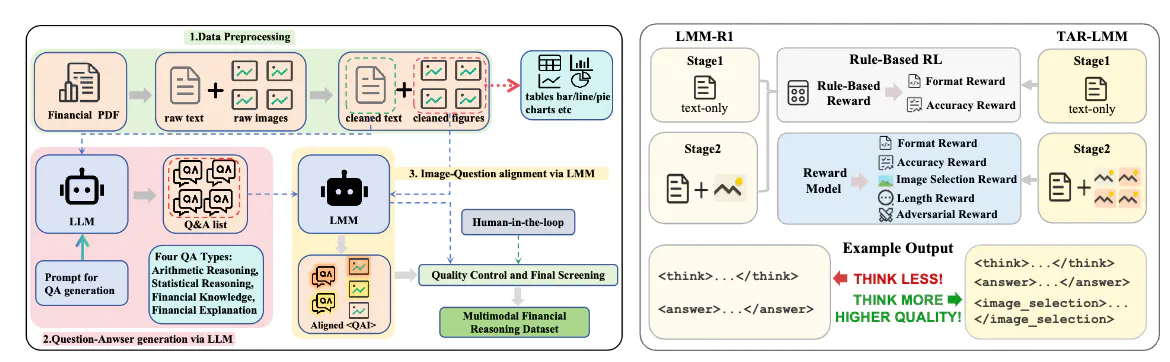
Large Multimodal Models (LMMs) demonstrate significant cross-modal reasoning capabilities. However, financial applications face challenges due to the lack of high-quality multimodal reasoning datasets and the inefficiency of existing training paradigms for reasoning enhancement. We propose FinLMM-R1, combining an automated and scalable pipeline for data construction with enhanced training strategies to improve the multimodal reasoning of LMM.
Type
Publication
Under Review