Parse, Align and Aggregate: Graph-driven Compositional Reasoning for Video Question Answering
Jan 1, 2026·,,,,,,,,,·
0 min read
Jiangtong Li
Zhaohe Liao
Fengshun Xiao
Tianjiao Li
Qiang Zhang
Haohua Zhao
Li Niu
Guang Chen
Liqing Zhang
Changjun Jiang
Abstract
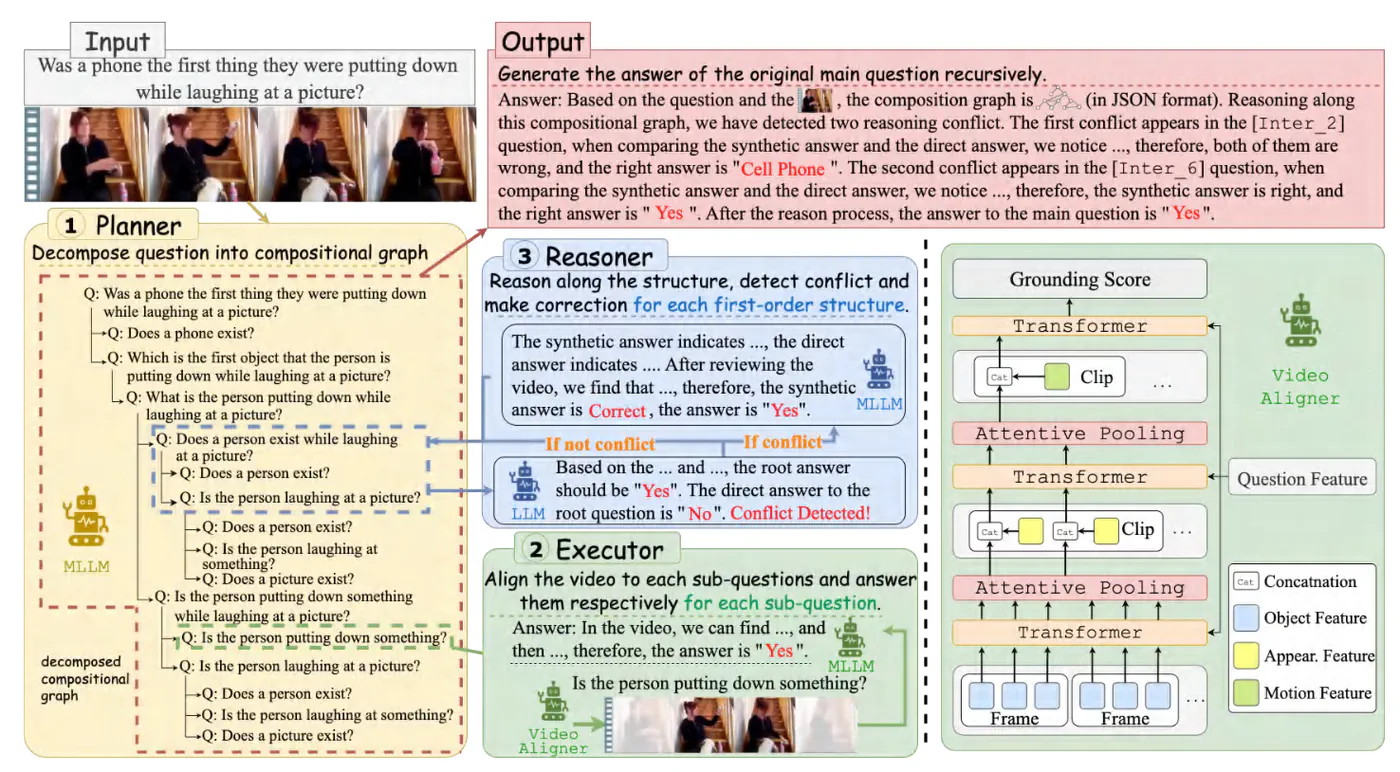
Video Question-Answering (VideoQA) enables machines to interpret and respond to complex video content, advancing human-computer interaction. However, existing multimodal large language models (MLLMs) often provide incomplete or opaque explanations and existing benchmarks mainly focus on the correction of final answers, limiting insight into their reasoning processes and hindering both transparency and verifiability. To address this gap, we propose the Question Parsing, Video Alignment and Answer Aggregation framework (QPVA3), which leverages a compositional graph to drive visual and logical reasoning in VideoQA. Specifically, QPVA3 consists of three core components, the planner, executor, and reasoner to generate the compositional graph and conduct graph-driven reasoning. For the original question, the planner parses it into the compositional graph, capturing the underlying reasoning logic and structuring it into a series of interconnected questions. For each question in compositional graph, the executor aligns the video by selecting relevant video clips and generates answers, ensuring accurate, context-specific responses. For each question with its first-order descents, the reasoner aggregates answers by integrating reasoning logic with visual evidence, resolving conflicts to produce a coherent and accurate response. Moreover, to assess the performance of existing MLLMs in the reasoning processes of VideoQA, we introduce novel compositional consistency metrics and construct a VideoQA benchmark (QPVA3Bench) with 3,492 question-video tuples, each annotated with detailed compositional graphs and fine-grained answers.
Type
Publication
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2026)