Video Semantic Segmentation via Sparse Temporal Transformer,
Oct 19, 2021·,,,,,,·
0 min read
Jiangtong Li
Wentao Wang
Junjie Chen
Li Niu
Jianlou Si
Chen Qian
Liqing Zhang
Abstract
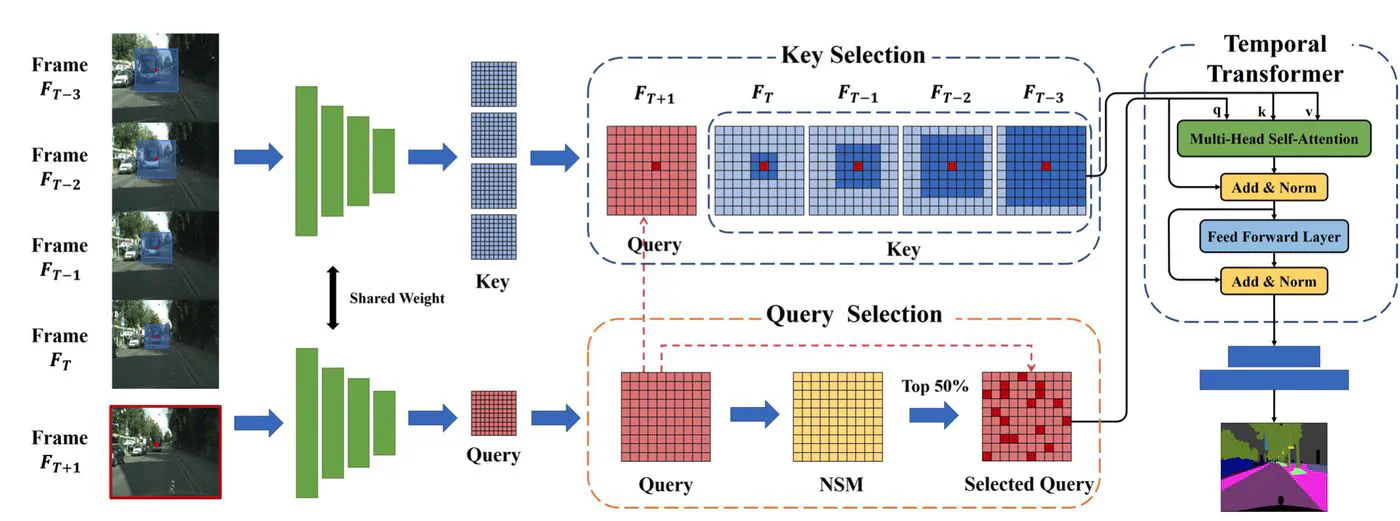
Currently, video semantic segmentation mainly faces two challenges: 1) the demand of temporal consistency; 2) the balance between segmentation accuracy and inference efficiency. For the first challenge, existing methods usually use optical flow to capture the temporal relation in consecutive frames and maintain the temporal consistency, but the low inference speed by means of optical flow limits the real-time applications. For the second challenge, flow-based key frame warping is one mainstream solution. However, the unbalanced inference latency of flow-based key frame warping makes it unsatisfactory for real-time applications. Considering the segmentation accuracy and inference efficiency, we propose a novel Sparse Temporal Transformer (STT) to bridge temporal relation among video frames adaptively, which is also equipped with query selection and key selection. The key selection and query selection strategies are separately applied to filter out temporal and spatial redundancy in our temporal transformer. Specifically, our STT can reduce the time complexity of temporal transformer by a large margin without harming the segmentation accuracy and temporal consistency. Experiments on two benchmark datasets, Cityscapes and Camvid, demonstrate that our method achieves the state-of-the-art segmentation accuracy and temporal consistency with comparable inference speed.
Type
Publication
The 29th ACM International Conference on Multimedia (ACM MM 2021)