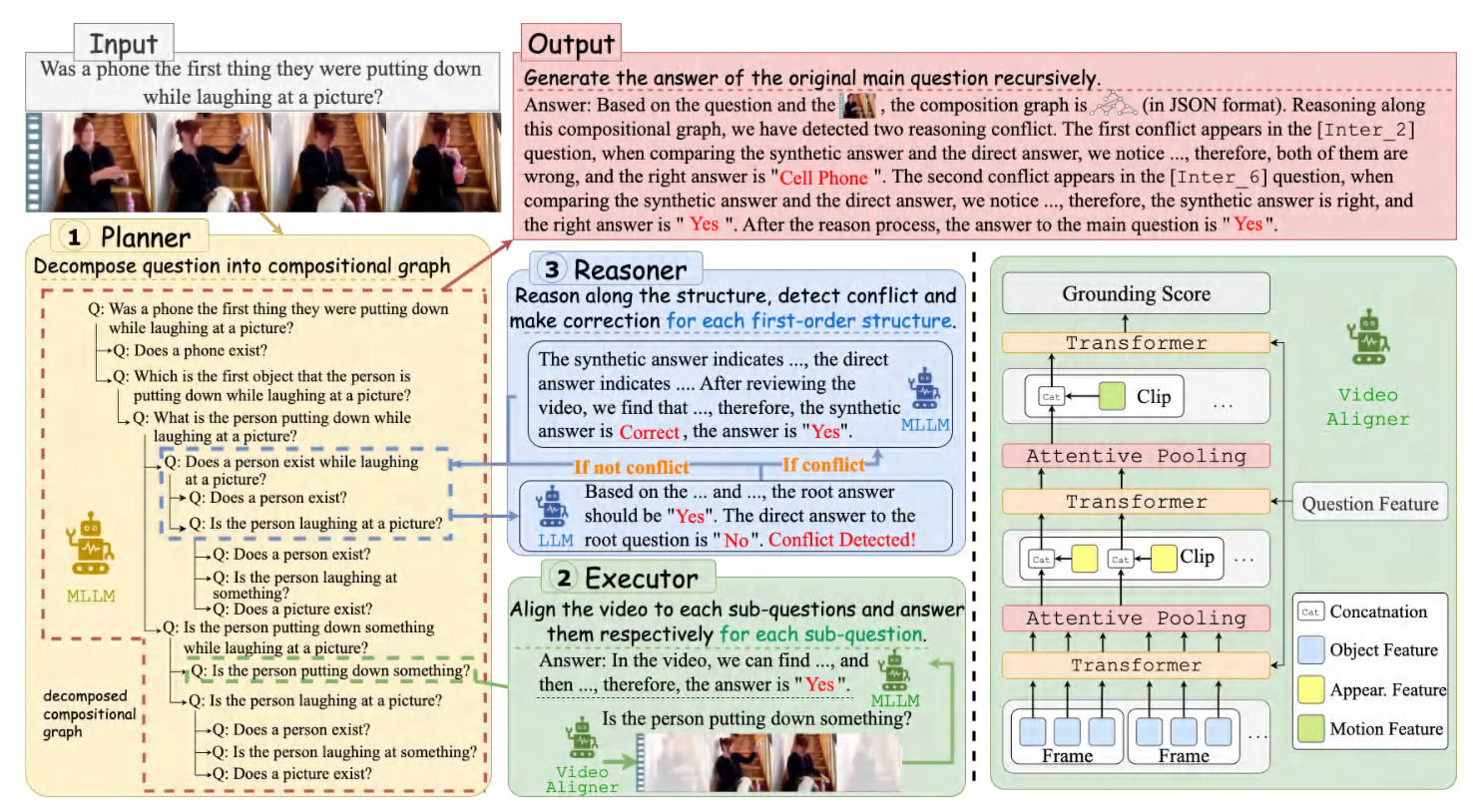
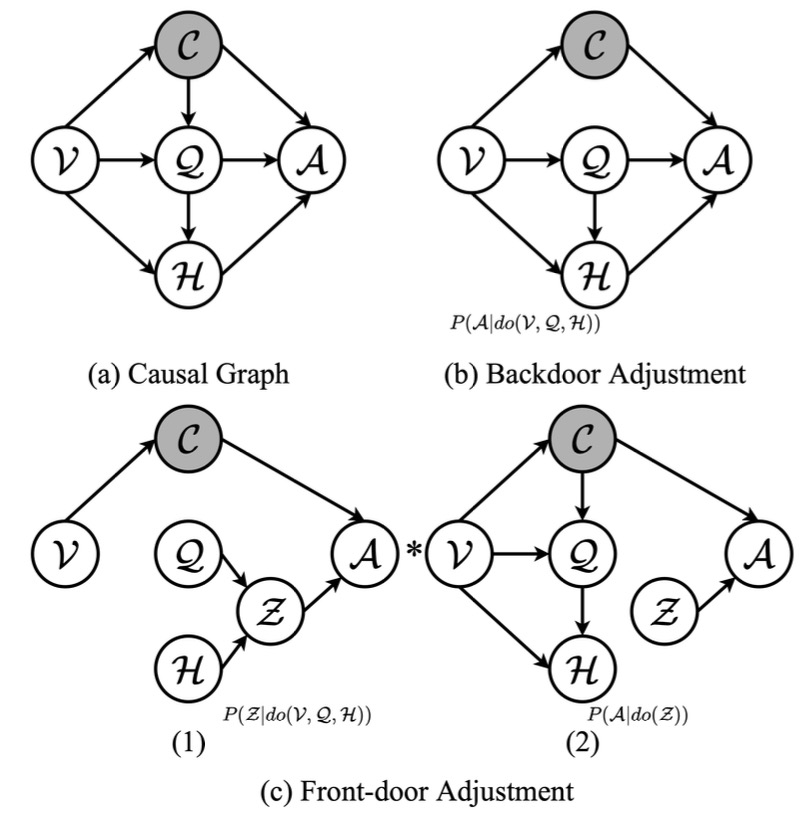
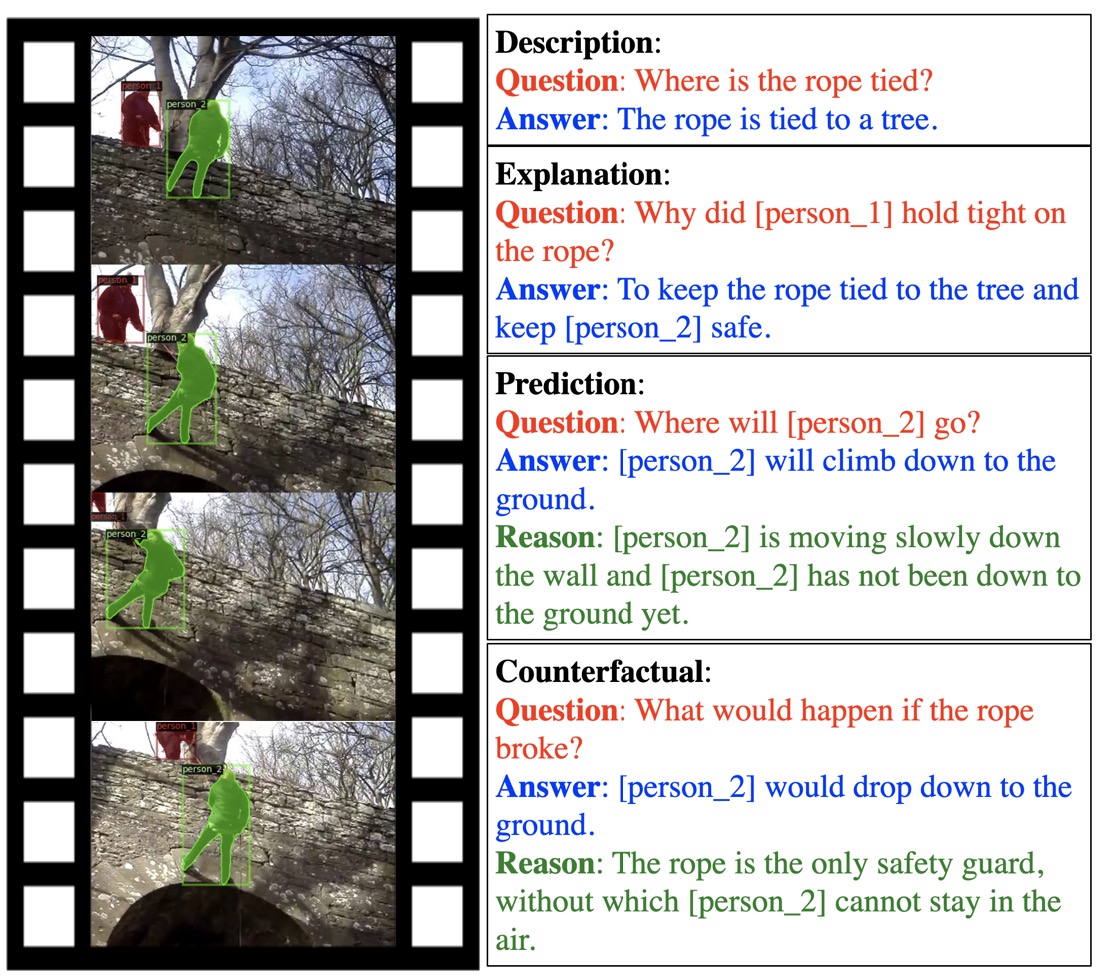
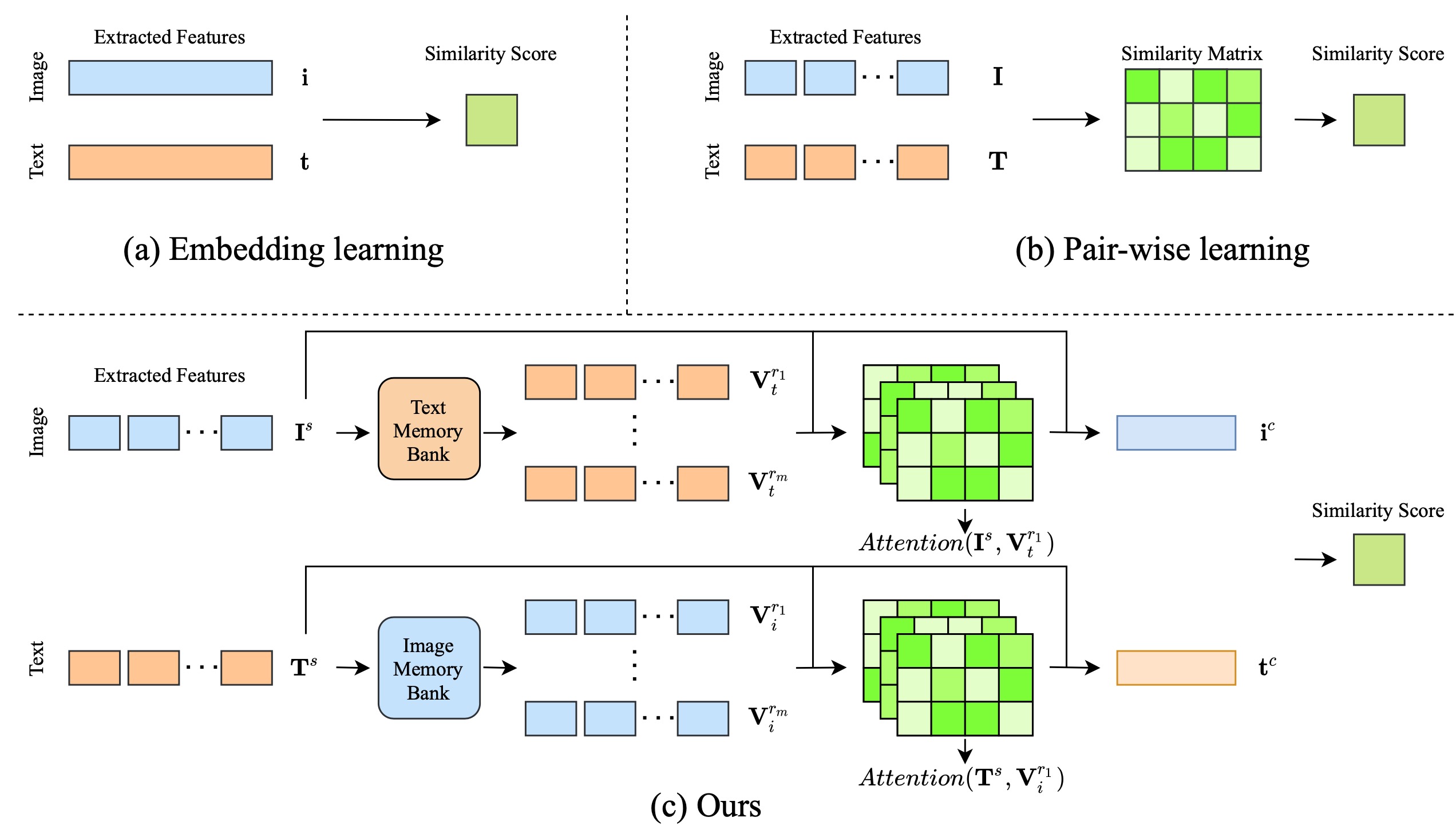
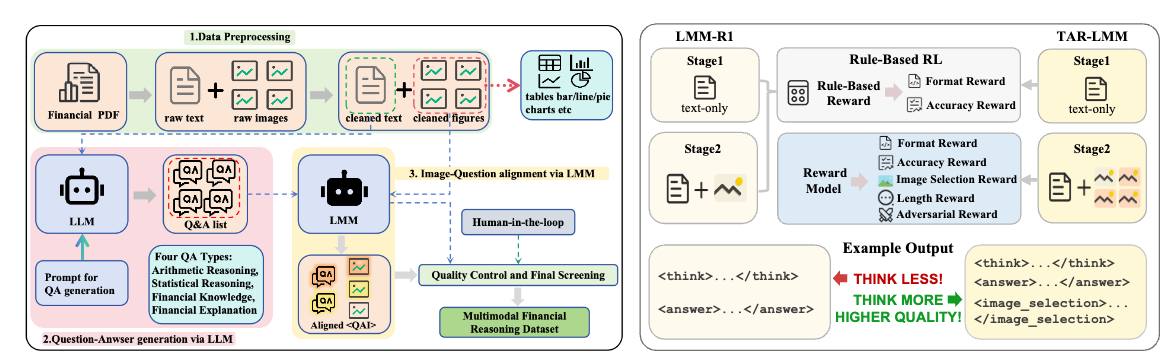
2026.05Six papers (five as Corresponding) on Multimodal Reasoning(x3), EEG Foundation Model(x2), and Graph Attack(x1) were accepted by ACL, ICML, IJCAI 2026, and KBS.
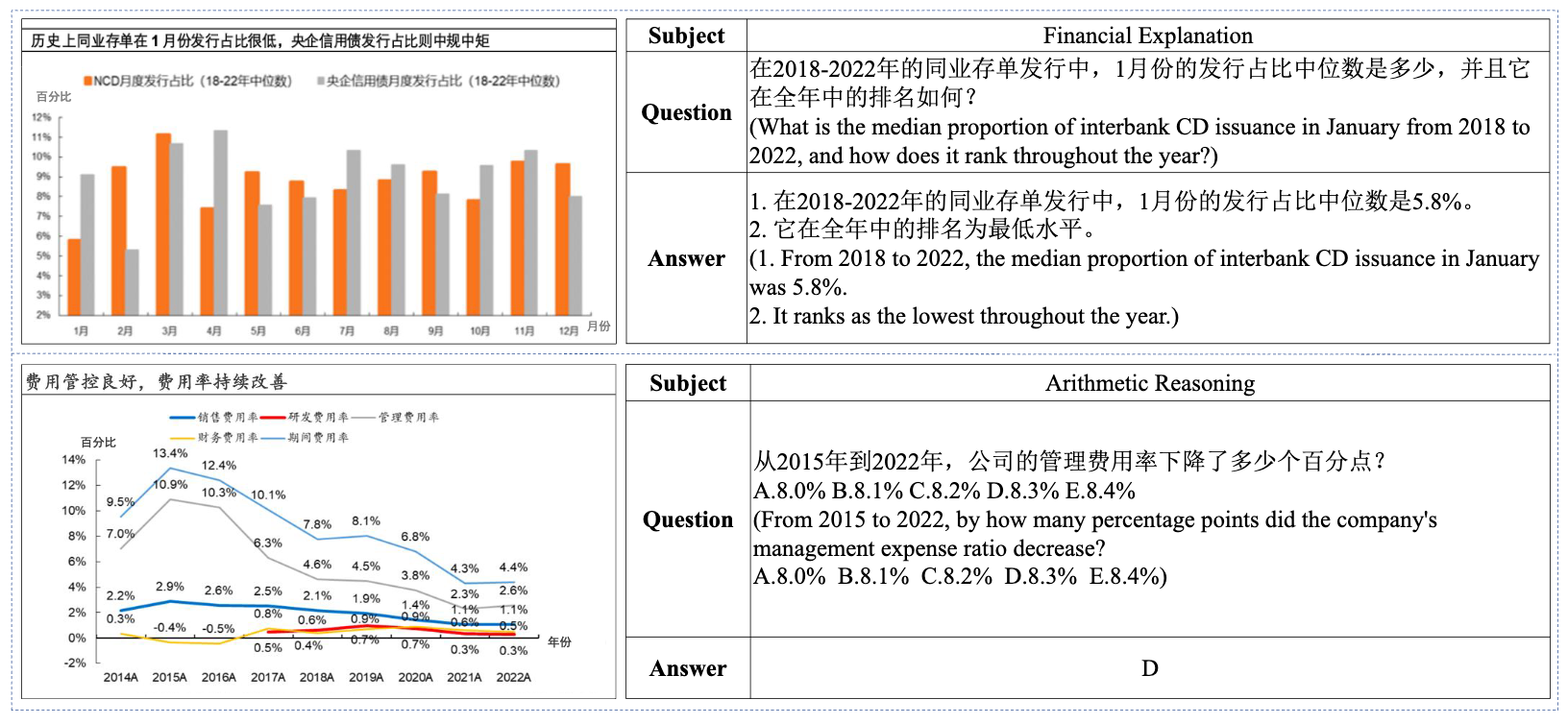
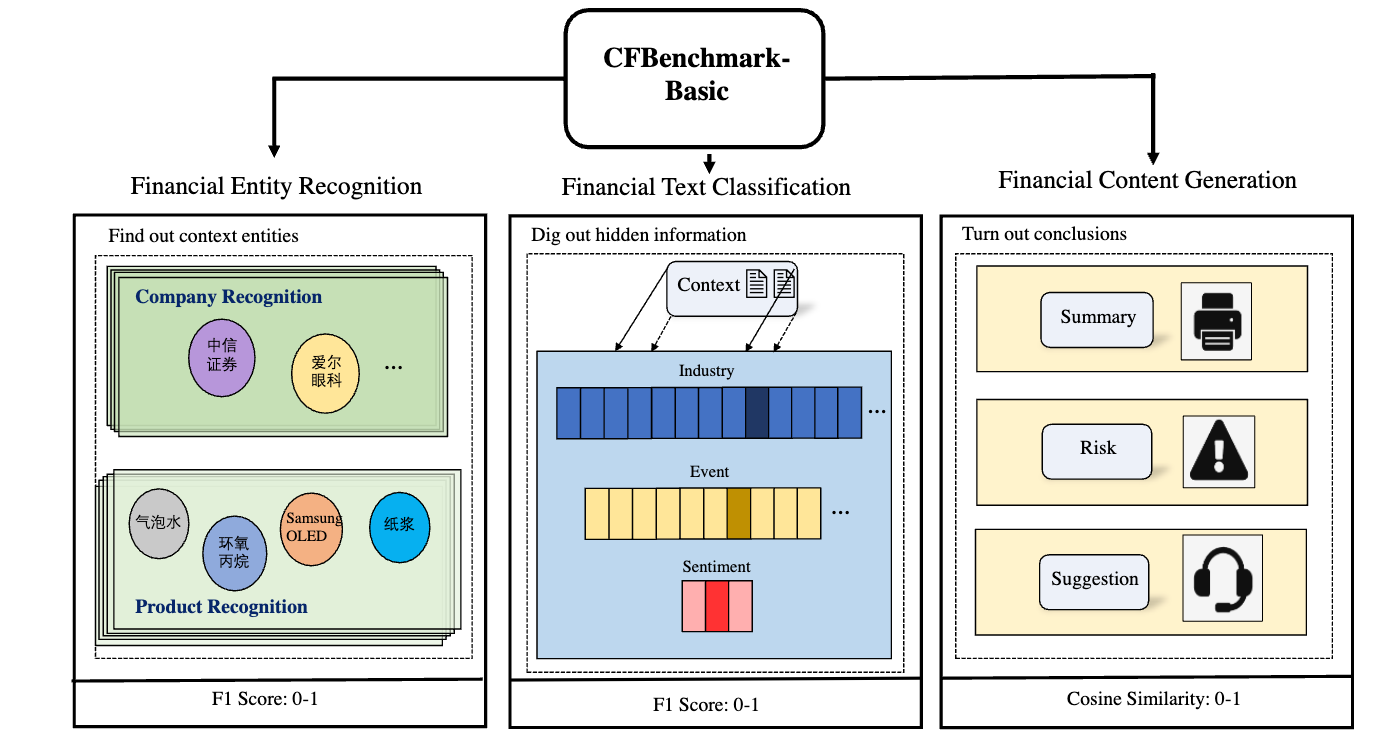
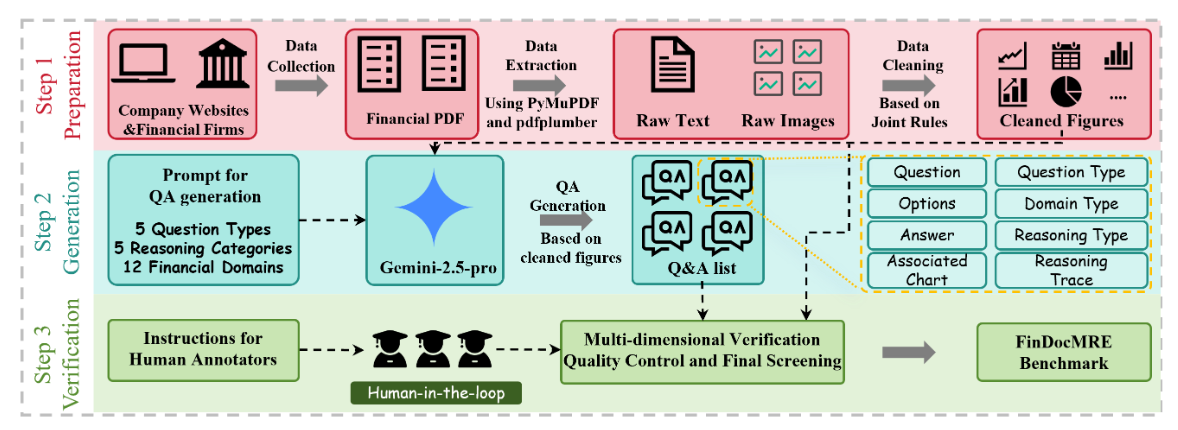
2026.04One paper (First Author) on LMM in Finance was accepted by BDMA.
2026.03One paper (Corresponding) on EEG Decoding was accepted by CVPR 2026.
2026.01Two papers (one as Corresponding) on Multimodal Reasoning(x1) and Anti-Fraud(x1) were accepted by WWW 2026.
2025.12One paper (First Author) on Multimodal Reasoning was accepted by IEEE TPAMI.
2025.11Two papers on LLM Efficiency(x1) and Anti-Fraud(x1) were accepted by HPCA and AAAI 2026.
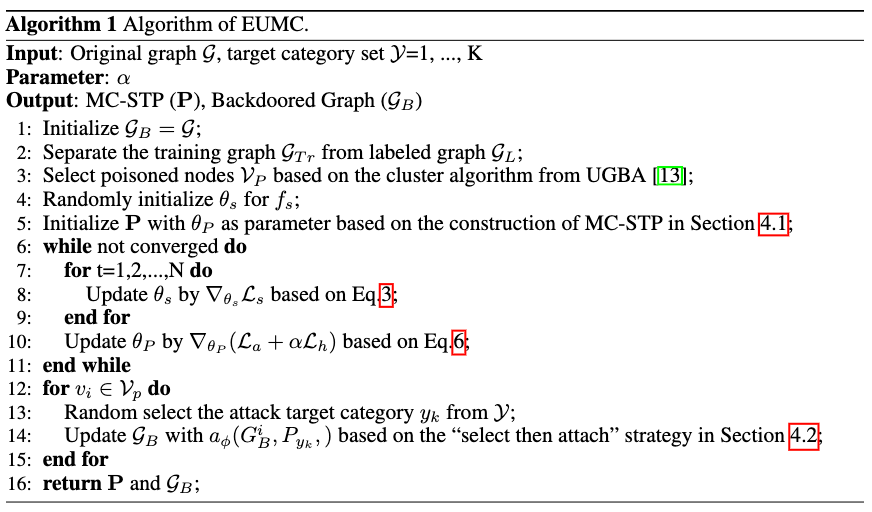
2025.09One paper (First Author) on Graph Attack was accepted by NeurIPS 2025.
2025.07I was awarded World Artificial Intelligence Conference Youth Outstanding Paper Honorable Mention (世界人工智能大会青年优秀论文提名奖).
2025.06My responsible China Postdoctoral Science Foundation was approved (中国博士后基金会面上项目).
2025.05One paper (Corresponding) on LLM4Debate was accepted by ACL 2025.
2025.05One paper (First Author) on LMM Reasoning was accepted by ICML 2025.
2025.03I was awarded Excellent Doctoral Dissertation (Honorable Mention) in Shanghai Jiao Tong University (上海交通大学优秀博士论文提名).
2025.01One paper on Long-tail Classification was accepted by ICLR 2025.
2024.12I was selected in Excellent PostDoc Program in Shanghai (上海市超级博士后).
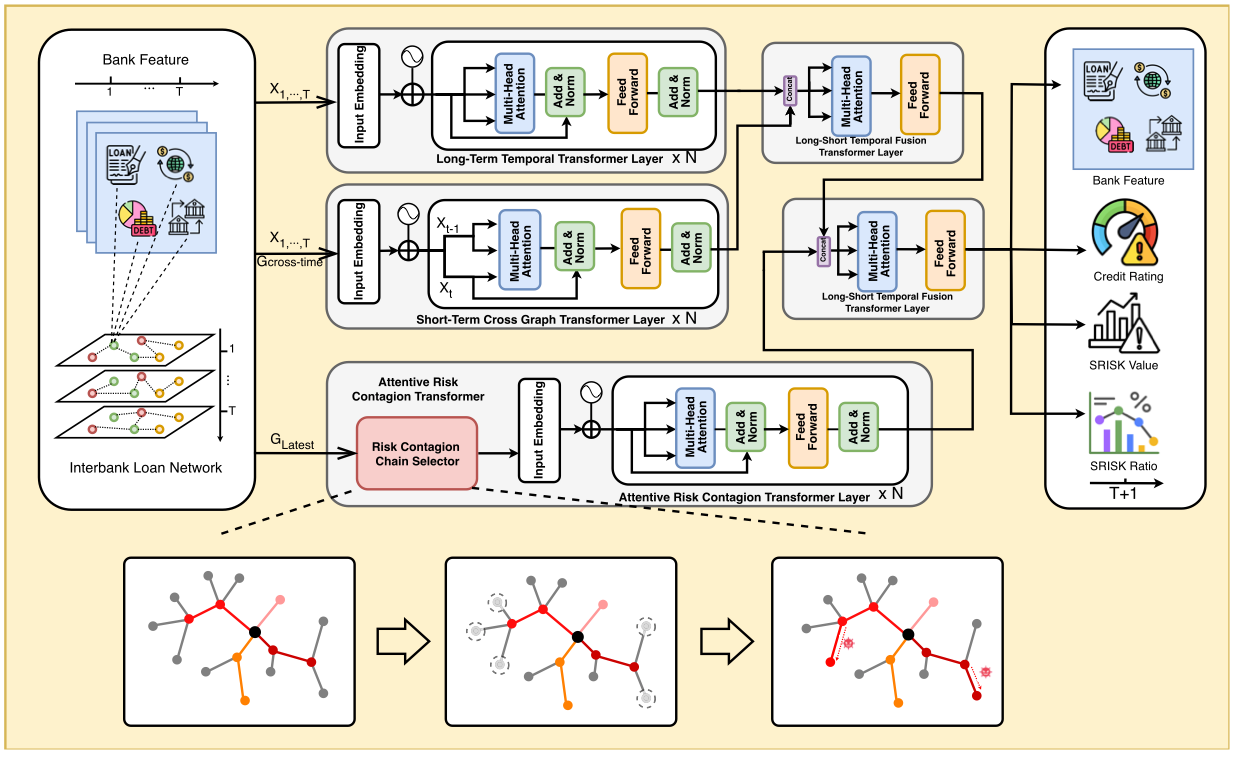
2024.11Two papers (First Author) on Interbank Risk in Finance(x1) and LLM in Finance(x1) were accepted by IEEE TNNLS and FCS.
2024.08My responsible National Science Foundation of China on Multimodal Reasoning was approved (国家自然科学基金委青年科学基金).
2024.07I was selected in Postdoctoral Fellowship Program of China Postdoctoral Science Foundation (博士后国家资助).
2024.07One paper on Causal Inference was accepted by ECCV 2024.
2024.05One paper (First Author) on Time Series was accepted by ICML 2024.
2024.04I was awarded Outstanding PhD Graduate in Shanghai (上海市优秀博士毕业生).
2024.03I graduated from Shanghai Jiao Tong University as PhD.
2024.02One paper (First Author) on LMM Reasoning was accepted by CVPR 2024.
2024.01I joined Tongji University as postdoctoral associate.
2023.08I was awarded Yang Yuanqing Excellent PhD Student Scholarship.
2023.08Two papers on Image Harmonization were accepted by ACM MM 2023.
2023.07One paper (First Author) on Multimodal Reasoning and Causal Inference was accepted by ICCV 2023.
2022.10I was awarded National Scholarship for PhD Students (博士生国家奖学金).
2022.08One paper (First Author) on Multimodal Retrieval was accepted by CVIU.
2022.03One paper (First Author) on Multimodal Reasoning was accepted by CVPR 2022.
2021.12One paper (First Author) on Multimodal Retrieval was accepted by AAAI 2022.
2021.10One paper (First Author) on Multimodal Retrieval was accepted by IEEE TIP.
2021.08One paper (First Author) on Video Segmentation was accepted by ACM MM 2021.
2020.12One paper on Multimodal Retrieval was accepted by AAAI 2021.